동적 계획법의 접근 방식
1단계: 동적 계획법 필요조건 분석하기
부분집합의 합과 같은 문제에 직면하게 되면
먼저 이 문제를 동적 계획법으로 해결할 수 있는지를 확인해야 한다.
일반적으로 주어진 문제가 다음 속성을 가지고 있다면 동적 계획법으로 해결할 수 있다.
- 중복되는 부분 문제 : 일반적인 분할 정복 기법과 마찬가지로,
최종해(final solution)는 여러 개의 부분 문제 조합으로 표현될 수 있어야 한다.
그러나 분할 정복과는 달리 특정 부분 문제가 여러번 발생할 수 있다. - 최적 부분 구조 : 주어진 문제에 대한 최적해(optimal solution)는
부분 문제의 최적해로부터 생성될 수 있다.

위 그림을 보면 크기가 n인 부분집합은 크기가 n - 1인 부분집합에 새로운 원소 하나를 추가하여 만들 수 있다.
이는 새로운 부분집합을 구성하기 위한 최적의 방법이며 크기가 0보다 큰 모든 부분집합에 적용된다.
그러므로 부분집합의 합 문제는 최적 부분 구조를 갖는다고 볼 수 있다.
또한 서로 다른 부분집합이 더 작은 크기의 같은 부분집합으로부터 생성될 수 있다.
예를 들어 부분집합 {13 79 45}와 {13 79 29}는 모두 더 작은 크기의 부분집합 {13 79}로부터 생성된다.
그러므로 부분집합의 합 문제는 중복되는 부분 문제 속성도 갖고 있다.
두 가지 조건을 모두 만족하기 때문에 부분집합의 합 문제는 동적 계획법으로 해결할 수 있다.
2단계: 기저 조건과 상태 정의하기
주어진 문제가 동적 계획법 문제임을 확인했다면
이제 이 문제에서 상태(state)를 구성하기 위해 필요한 것이 무엇인지 파악해야 한다.
즉, 각 부분 문제를 다른 부분 문제와 다르다고 판단할 수 있는 기준을 찾아야 한다.
처음부터 동적 계획법 문제의 상태를 제대로 정의하여 해를 구할 수 있다면 매우 바람직하겠지만,
주어진 문제의 최적해가 어떻게 구성되는지에 대한 명확한 이해 없이 상태를 정의하는 것은 쉽지 않다.
그러므로 문제의 해를 구하기 위한 가장 직관적인 방법부터 구현해보는 것도 좋다.
여기서는 비교적 구현하기 쉬운 두 가지 방법으로 부분집합의 합 문제를 해결해보면서
이 문제의 기저 조건과 상태에 대해 알아보겠다.
동적 계획법에 대해 알아보면서
전수 조사, 백트래킹, 메모이제이션, 타뷸레이션이라는 네 가지 접근 방법을 고려할 것이다.
이들 네 가지 접근 방법은 모든 동적 계획법 문제에서 정확한 결과를 제공하지만,
처음 세 방법은 입력 크기가 증가함에 따라 그 한계가 금방 드러나게 된다.
그럼에도 이들 방법을 차례대로 구현해보면 다양한 동적 계획법 문제를 해결할 때
큰 효과를 볼 수 있다.
2-(a)단계: 전수 조사
전수 조사(brute-force) 방법은 분명히 비효율적이지만
현재 다루고 있는 문제를 제대로 이해하는데 도움이 된다.
전수 조사 방법을 구현하는 것은
동적 계획법 문제의 해를 구하는 과정에 있어서 필수적인 단꼐가 될 수 있으며,
여기에는 다음과 같은 이유가 있다.
- 단순성 :
효율성에 대한 고려 없이 단순한 방법으로 문제의 해를 구하는 작업은
주어진 문제의 근본적인 속성을 이해하는 데 도움이 된다.
주어진 문제에 대한 충분한 이해 없이 복잡한 방법으로 접근하는 것보다
최대한 단순하게 접근하는 것이 문제의 본질을 이해하기 쉽다. - 정답 비교를 위한 수단 :
몇몇 복잡한 동적 계획법의 문제의 경우,
주어진 문제를 충분히 이해하게 되면 상당히 많은 재설계가 필요할 수 있다.
이 때문에 동적 계획법으로 구한 해답과 비교할 수 있는 정답을 가지고 있을 필요가 있다. - 부분 문제를 시각화하는 능력 :
전수 조사 방법은 가능한 모든 방법을 생성한 후,
문제의 조건을 만족하는 해를 찾는 방법이다.
이러한 방법은 올바른 해답이 형성되는 방식을 시각화하는 수단을 제공할 수 있으며,
이를 이용하여 다른 풀이 방법에서 사용할 수 있는 필수 패턴을 찾을 수 있다.
다음 연습 문제에서 부분집합의 합 문제를 전수 조사 방식으로 풀어보겠다.
연습 문제 36 : 전수 조사 방식으로 부분집합의 합 문제 풀기
이번 연습 문제에서는 전수 조사 방식을 이용하여 부분집합의 합 문제에 대한 해를 구해보겠다.
1. 필요한 헤더 파일을 포함한다.
그리고 편의를 위해 std 네임스페이스 사용을 선언한다.
#include <iostream>
#include <vector>
#include <algorithm>
2. 부가적인 기능으로 DEBUG라는 전처리기 상수와 PRINT라는 매크로 함수를 정의하고,
DEBUG가 0이 아닌 경우에만 stderr 출력을 수행하도록 설정한다.
#define DEBUG 0
#if DEBUG
#define PRINT(x) cerr << x
#else
#define PRINT(x)
#endif
3. 집합의 모든 부분집합을 구하는 GetAllSubsets() 함수를 정의한다.
이 함수는 두 개의 정수 벡터 set과 subset, 정수 index,
그리고 모든 부분집합을 저장할 3차원 정수 벡터 allSubsets 를 인자로 받는다.
이때 allSubsets는 참조로 전달한다.
이 함수는 재귀 호출을 이용하여 set의 모든 부분집합을 생성한다.
void GetAllSubsets(vector<int> set, vector<int> subset, int index, vector<vector<vector<int>>>& allSubset)
{
// 집합 set의 끝에 다다른 경우
if (index == set.size())
{
// 부분집합 크기를 인덱스로 사용하여 부분집합을 allSubsets에 추가
allSubset[subset.size()].push_back(subset);
return;
}
// 원소를 추가하지 않고 재귀 호출
GetAllSubsets(set, subset, index + 1, allSubset);
// 원소를 부분집합에 추가한 후 재귀 호출
subset.push_back(set[index]);
GetAllSubsets(set, subset, index + 1, allSubset);
}
이렇게 차근차근 함수를 만들어 나가면 다음과 같다.
#include <iostream>
#include <vector>
#include <algorithm>
#define DEBUG 0
#if DEBUG
#define PRINT(x) cerr << x
#else
#define PRINT(x)
#endif
using namespace std;
void GetAllSubsets(vector<int> set, vector<int> subset, int index, vector<vector<vector<int>>>& allSubset)
{
// 집합 set의 끝에 다다른 경우
if (index == set.size())
{
// 부분집합 크기를 인덱스로 사용하여 부분집합을 allSubsets에 추가
allSubset[subset.size()].push_back(subset);
return;
}
// 원소를 추가하지 않고 재귀 호출
GetAllSubsets(set, subset, index + 1, allSubset);
// 원소를 부분집합에 추가한 후 재귀 호출
subset.push_back(set[index]);
GetAllSubsets(set, subset, index + 1, allSubset);
}
bool SubsetSum_BruteForce(vector<int> set, int target)
{
vector<vector<vector<int>>> allSubsets(set.size() + 1);
GetAllSubsets(set, {}, 0,allSubsets);
for (int size = 0; size <= set.size(); size++)
{
PRINT("부분집합의 원소 개수 : " << size << endl);
for (auto subset : allSubsets[size])
{
PRINT("\t{ ");
int sum = 0;
for (auto number : subset)
{
sum += number;
PRINT(number << " ");
}
PRINT("} =" << sum << endl);
if (sum == target)
{
return true;
}
}
}
return false;
}
int main()
{
vector<int> set = { 13,97,45,29 };
int target = 58;
bool found = SubsetSum_BruteForce(set, target);
if (found)
{
cout << "원소 합이 " << target << "인 부분집합이 있습니다." << endl;
}
else
{
cout << "원소 합이" << target << "인 부분집합이 없습니다." << endl;
}
}

2-(b)단계: 최적화 적용하기 - 백트래킹
사실 전수 조사 방식은 사용하기가 좀 마땅치 않았다.
성능 면에서 가장 비효율적인 방법이기 때문이다.
가능한 모든 부분집합을 무차별적으로 확인하기 때문에
더 이상 해답이 나올 수 없는 경우에 대해서도 모든 조사를 수행해야 한다.
예를 들어 위의 연습 문제와 같은 경우, 부분집합의 합이 target 값보다 커지는 경우에도
계속 부분집합에 원소를 추가하며 검사를 수행했다.
알고리즘을 개선하기 위해 모든 부분 문제 중에서
유효하지 않은 모든 경우를 제거하는 백트래킹 기법을 사용할 수 있다.
백트래킹 방법을 구현하려면 주어진 문제의 기저 조건과 상태의 재귀적 표현을 결정해야 하며,
이러한 작업은 이후 동적 계획법을 적용할 떄 도움이 된다.
이 장의 앞부분에서 정의했듯이,
기저조건이란 재귀 함수에서 추가적인 재귀 호출을 수행하지 않고
해를 구할 수 있는 경우를 의미한다.
이해를 돕기 위해 팩토리얼 (factorial)을 계산하는 경우를 예로 들어보겠다.
정수 n의 팩토리얼은 n * (n-1) * (n-2) * (n-3) * . . . * 1 수식으로 계산된다.
팩토리얼을 계산하는 C++ 함수를 다음과 같이 작성할 수 있다.
int Factorial(int n)
{
// 기저 조건 - 재귀 호출 멈추기
if (n == 1)
{
return 1;
}
// 기저 조건을 만날 때까지 재귀 호출 수행
return n * Factorial(n - 1);
}
이 함수를 이용하여 Factorial(5)를 구하는 동작을 그림으로 나타내 보았다.
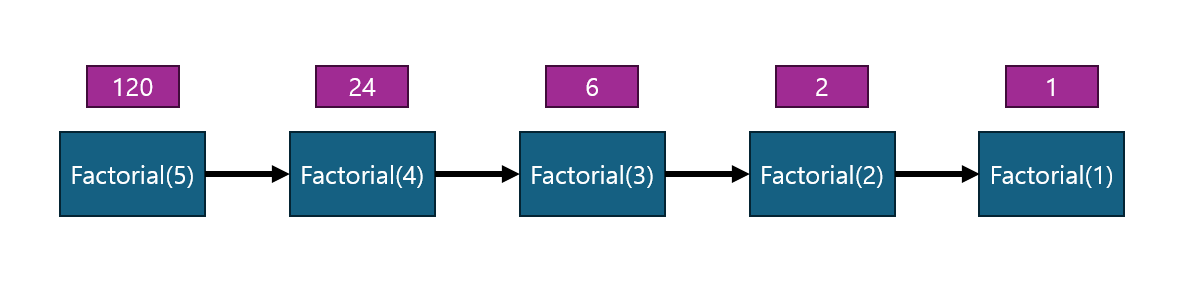
팩토리얼 계산에서는 n = 1인 경우에 재귀 호출을 하지 않고 함수가 반환되므로
n = 1인 경우가 기저 조건이 된다.
부분집합 합 문제에서는 다음과 같이 기저 조건을 정의할 수 있다.
만약 현재 부분집합의 합이 target과 같다면 : TRUE
그렇지 않다면 :
- 만약 현재 부분집합의 합이 target보다 크면 : FALSE
- 만약 집합의 끝에 도달한 경우 : FALSE
기저 조건을 만들었으니 이제 상태 변화 방법을 정의해야 한다.
이를 위해 앞서 구현한 전수 조사 방법의 출력 결과를 참고하여 같은 크기의 부분집합들이
어떻게 형성되는지를 분석해보겠다.

부분집합의 크기가 0에서 1로 변하는 경우 쉽게 이해할 수 있다.
공집합에 집합 원소를 하나씩 추가하는 방식으로 크기가 1인 부분집합을 생성할 수 있다.

비슷한 방식으로 크기가 2인 부분집합을 만들 수 있다.
크기가 1인 집합을 선택하고, 이 부분 집합이 가지고 있는 원소의 인덱스보다
큰 인덱스의 원소를 원본 집합에서 하나씩 골라 추가한다.
이는 전수 조사 방식에서 구현했던 것과 같은 방식이다.
다만 이번에는 매번 부분집합의 합을 계산하고,
목표치(target)보다 큰 경우에는 동작을 중지할 것이다.


목표치 값이 58이기 때문에 크기가 3 또는 4인 부분집합은
고려할 필요가 없다는 점을 알 수 있다.
그러므로 상태 변화 방식을 다음과 같이 정의할 수 있다.
집합 set의 i번째 원소 set[i]와 부분집합 ss에 대해 :
만약 ss의 합 set[i]를 더한 결과가 target보다 작거나 같으면 :
1) ss에 set[i]를 추가
2) i를 증가
다음 상태 -> ( i = i + 1, ss = ss U set[i])
모든 경우에 대해 :
1) ss에 set[i]를 추가하지 않음
2) i 증가
다음 상태 -> (i = i + 1, ss = ss)
이제 물음에 대해 생각을 해보겠다.
- 현재 상태를 표현하기 위해 필요한 최소 데이터양은 얼마인가?
- 불필요한 정보를 제거하기 위해 앞서 설명한 논리를 어떻게 재구성할 것인가?
부분집합의 합 문제 정의를 다시 생각해보겠다.
이 문제는 주어진 집합의 부분집합 중에서
그 합이 정수 target과 같은 부분집합이 잇는지를 판별하는 것이 목적이다.
문제 정의에 의하면 풀이 과정에서 실제 부분집합이 어떻게 구성되는지는 나타낼 필요가 없고,
단지 그 부분집합의 합만 검사하면 된다.
그러므로 상태 변화 의사 코드를 다음과 같이 간결하게 변경할 수 있다.
집합 set의 i번째 원소 set[i]와 부분집합 합 sum에 대해 :
만약 sum에 set[i]를 더한 결과가 target보다 작거나 같으면 :
1) sum에 set[i]를 더함
2) i 증가
다음 상태 -> (i = i + 1, sum = sum + set[i] )
모든 경우에 대해 :
1) sum에 set[i]를 더하지 않음
2) i 증가
다음 상태 -> ( i = i + 1, sum = sum)
이러한 의사 코드를 사용하면 중간 단계 상태를 sum과 i 두 개의 정수로 표현할 수 있다.
최악의 경우 2^n개로 구성될 수 있는 부분집합 배열을 사용하지 않아도 된다.
또한 문제 접근 방식을 target값부터 시작해서 매 단계마다 set[i] 값을 빼는 형태로 전환하면
target 값을 가지고 다니지 않게끔 만들 수도 있다.
마지막 최적화 방법으로 함수 호출 전에 집합을 정렬함으로써
target보다 값이 커지는 경우를 만나면 나머지 집합 원소는 고려하지 않도록 만들 수도 있다.
3단계: 메모이제이션
백트래킹 방법이 전수 조사 방법보다는 훨씬 우수하지만 여전히 최선의 방법은 아니다.
부분집합의 합 목표치가 매우 큰 경우에 대해 생각해보겠다.
만약 목표치가 입력 집합의 모든 원소의 합보다 같거나 크다면 사전에
입력 집합의 원소 합을 미리 꼐산하여 목표치가 유효한 범위 안에 있는지를 검사할 수 있을 것이다.
그러나 목표 합이 입력 집합의 모든 원소 합보다 미세하게 작다면
알고리즘 전체를 실행하여 모든 가능한 경우를 확인해야 한다.
메모이제이션이라는 하향식 방법을 사용하면 필요한 모든 정보를 이미 가지고 있다.
더군다나 메모이제이션을 구현하기 위해 기존에 사용했던 방법을 수정할 필요도 없다.
캐시 사용하기
메모이제이션을 사용하는 데 있어 가장 중요한 것은
캐시를 어떻게 사용할 것인지를 결정하는 것이다.
메모이제이션을 위한 캐시는 다양한 방식으로 정의할 수 있지만,
일반적인 방법은 다음과 같다.
- 정수 인덱스를 사용하는 일반 배열
- 프로그래밍 언어에서 제공하는 해시 기능을 사용하여
상태를 문자열로 표현한 해시 테이블 또는 해시 맵 - 자체적으로 생성한 해시 함수를 이용하여 상태를 표현한 해시 테이블 또는 해시 맵
여기서 어떤 것을 선택할 것인지는 주어진 상황에 따라 다르겠지만,
몇 가지 일반적인 지침은 다음과 같다.
- 정수 인덱스를 사용하는 배열과 벡터는 일반적으로 맵보다 빠르다.
맵은 이미 캐시가 존재하는지를 확인하기 위해
주어진 키에 해당하는 위치를 찾는 작업이 필요하기 때문이다. - 상태를 정수로 표현할 수 있다고 하더라도 그 값이 너무 크게 나타날 경우,
실제 필요한 메모리보다
훨씬 큰 크기의 배열을 만들어 사용해야 하기 때문에 비합리적일 수 있다.
이러한 경우에는 맵을 사용하는 편이 나을 수 있다. - std::unordered_map과 같은 해시 테이블은
일반적인 맵 / 딕셔너리 구조보다 빠르게 키를 찾고 검색할 수 있다
(그러나 여전히 배열보다는 느리다). - std::map은 키로 사용할 수 있는 자료형 측면에서
std::unordered_map보다 훨씬 자유도가 높다.
std::unordered_map은 기술적으로 동일하 ㄴ기능을 제공할 수 있지만,
기본적으로 키로 사용할 수 없는 자료형에 대해서는 프로그래머가
직접 해싱 함수를 만들어야 한다.
캐시 사용 방법은 다음을 만족해야 한다.
- 유효성 :
캐시의 키 값은 서로 다른 상태에 대해 충돌이 발생하지 않도록 표현되어야 한다. - 유용성 :
캐시 사용 방식이 너무 독특해서 캐시에 저장된 값을
참조하는 경우가 아예 발생하지 않는다면 아무 의미가 없다.
부분집합의 합 문제에서 부분집합의 합을 상태로 사용할 경우,
특정 sum 값을 갖는 상태에서 목표치를 찾지 못한다는 것이 같은 sum 값을 갖는
다른 상태에서도 목표치를 찾지 못한다고 잘못 인식할 수 있다.
즉, if (memo[sum] != UNKNOWN) return memo[sum]; 형태의 코드를 사용하면 문제가 발생할 수 있다.
4단계: 타뷸레이션
주어진 집합에 대해 가능한 모든 부분 집합의 합 목록을 얻고 싶다고 가정해보자.
공집합부터 전체 집합의 총합까지, 각각의 부분집합의 합을 구하기 위해
알고리즘을 반복적으로 실행해야 한다.
이러한 경우에는 타뷸레이션 방법이 효과적이다.
이와 같은 문제에서 표를 사용하는 형태의 해법을 구현한다는 것을
개념화하기에는 쉽지 않다.
주어진 문제를 재귀식으로 표현하는 것은 다차원 상태 표현과 분기 구조에는 잘 부합하지만,
표형식 해법은 복잡한 계층을 for/while 문법에 의한 단순한 반목문 구조로 표현해야 한다.
이러한 구조 변경을 위해 사용되는 몇몇 기법들이 존재하지만,
궁극적으로는 올바른 일반화를 할 수 있을 정도로
주어진 문제를 얼마나 잘 이해하고 있는지 여부가 중요하다.
메모이제이션과 마찬가지로 기저 조건과 상태를 정의한 후
해야 할 첫 번째 작업은 서로 다른 상태에 대한 해법을 어떻게 저장할 것인지를 결정하는 것이다.
일반적으로 타뷸레이션 방법에서는 간단한 배열 또는 벡터를 사용한다.
타뷸레이션은 단순히 반복문을 이용하여 계산하기 때문에
상향식 로직과 하양식 로직으로 나눌 수 있다.
메모이제이션과 비슷하지만 값을 미리 계산해둔다는 점에서 다르다.
메모이제이션은 결과가 필요해질 때 계산한다면,
타뷸레이션은 필요하지 않은 값도 미리 계산해둔다는 차이가 있다.
초기화 오버헤드가 있지만,
일단 계산해둔 값은 시간복잡도가 상수 시간 (O(1))이 된다.
'컴퓨터 프로그래밍 공부 > 자료구조와 알고리즘' 카테고리의 다른 글
| 완벽한 해싱 & 유니버설 해싱 (0) | 2024.06.15 |
|---|---|
| 삽입 정렬과 힙 정렬 (0) | 2024.06.12 |
| 우선순위 큐 (0) | 2024.06.06 |
| 동적 계획법 (1) (0) | 2024.05.18 |
| Tree (0) | 2024.04.28 |