테이블이란?
테이블이란 영어를 단순 번역하면 표이다.
하지만 자료구조에서 으래 말하는 테이블의 이해하기 좋은
대표적인 예는 사전을 생각하면 된다.
사전에서 단어는 Key가 되고, 단어의 뜻이나 내용은 Value가 된다.
즉 테이블에 저장되는 데이터는 Key와 Value가 하나의 짝을 이루는 것이다.
배열을 기반으로 하는 테이블
테이블 자료구조를 배열을 기반으로
제작하여 누구나 쉽게 이해할 수 있는 예제는 아래와 같다.
#include <stdio.h>
#pragma warning(disable:4996)
typedef struct _empInfo
{
int empNum;
int age;
} EmpInfo;
int main(void)
{
EmpInfo empInfoArr[1000];
EmpInfo ei;
int eNum;
printf("사번과 나이 입력 : ");
scanf("%d %d", &(ei.empNum), &(ei.age));
empInfoArr[ei.empNum] = ei;
printf("확인하고픈 직원의 사번 입력 : ");
scanf("%d", &eNum);
ei = empInfoArr[eNum];
printf("사번 %d, 나이 %d \n", ei.empNum, ei.age);
return 0;
}

위 구조체에서 어디가 Key Value인지 확인해보면 아래와 같다.
typedef struct _empInfo
{
int empNum; // Key
int age; // Value
} EmpInfo;
이는 키와 값을 하나의 쌍으로 묶기 위해서 정의된 구조체임을 알 수 있다.
그렇다면 이 구조체를 기반으로 하는 배열을 선언하면, 테이블이 될까?
EmpInfo empInfoArr[1000];
이 배열을 가리켜 테이블이라 하기엔 부족하다.
물론 단순한 배열도 테이블이 될 수 있지만,
테이블이 되기 위해서는 다음 조건을 만족해야 한다.
"키를 결정하였다면, 이를 기반으로 데이터를 단번에 찾을 수 있어야 한다"
라는 조건을 충족해야 한다는 것이다.
즉 테이블에서 의미하는 키는 데이터를 찾는 도구가 되어야 한다.
그것도 단번에 찾을 수 있는 도구가 되어야 한다.
- 저장 empInforArr[ei.empNum] = ei;
- 탐색 ei = empInfoArr[eNum];
이 두 문장으로 알 수 있는 사실은 다음과 같다.
직원의 고유번호를 인덱스 값으로 하여, 그 위치에 데이터를 저장한다.
이렇듯 키의 값은 저장위치라는 관계를 형성하여,
단번에 데이터를 저장하고 단번에 데이터를 탐색할 수 있게 하였다.
따라서 위 배열은 필요충분조건을 만족하여 테이블을 구현한 것이 맞게 된다.
하지만 위 배열은 이번 포스팅의 핵심인 해쉬와 관련된 내용은 빠졌다.
테이블에 의미를 부여하는 해쉬 함수와 충돌문제
예제에서 보인 테이블과 관련하여
문제점 두 가지를 정리하면 다음과 같다.
"직원 고유의 번호가 배열의 인덱스 값으로 사용하기에 적당하지 않다"
"직원 고유번호의 범위를 수용할 수 있는 매우 큰 배열이 필요하다"
이 두 가지 문제를 동시에 해결해주는 것이 '해쉬 함수'이다.
일단, 고유번호 범위 수용에 대한 문제를 해결하고자
직원의 고유번호를 입사 년도 네 자리와 입사순서 네 자리로 구성하며 코드를 작성해보면
아래의 코드와 같다.
#include <stdio.h>
#pragma warning(disable:4996)
typedef struct _empInfo
{
int empNum;
int age;
} EmpInfo;
int GetHashValue(int empNum)
{
return empNum % 100;
}
int main(void)
{
EmpInfo empInfoArr[1000];
EmpInfo ei;
int eNum;
EmpInfo emp1 = { 20120003, 42 };
EmpInfo emp2 = { 20130012,33 };
EmpInfo emp3 = { 20170049,27 };
EmpInfo r1, r2, r3;
// 키를 인덱스 값으로 이용해서 저장
empInfoArr[GetHashValue(emp1.empNum)] = emp1;
empInfoArr[GetHashValue(emp2.empNum)] = emp2;
empInfoArr[GetHashValue(emp3.empNum)] = emp3;
// 키를 인덱스 값으로 이용해서 탐색
r1 = empInfoArr[GetHashValue(20120003)];
r2 = empInfoArr[GetHashValue(20130012)];
r3 = empInfoArr[GetHashValue(20170049)];
// 탐색 결과 확인
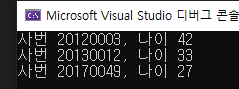
printf("사번 %d, 나이 %d\n", r1.empNum, r1.age);
printf("사번 %d, 나이 %d\n", r2.empNum, r2.age);
printf("사번 %d, 나이 %d\n", r3.empNum, r3.age);
return 0;
}
위 예쩨는 직원의 수가 100명을 넘길 경우를 고려하지 않았다.
그리고 데이터의 저장위치를 결정하는데 있어서 직원의 고유번호를 활용하되,
함수를 이용하는 가공 과정을 거쳤다.
100으로 % 연산을 하는 것은
여덟 자리의 수로 이뤄진 직원의 고유번호를 두 자리의 수로 변경한다는 의미이다.
그럼 100으로 나눠서 그 나머지를 취하는 이 연산을 f(x)라 하면,
f(x)를 가리켜 해쉬 함수라 한다.
즉, 해쉬 함수란
해쉬 함수는 넓은 범위의 키를 좁은 범위의 키로 변경하는 역할을 한다.
그럼 이어서 해쉬 함수를 적용하였다고 하더라도,
직원 수가 100명을 넘어갔을 때, 충돌이 생기게된다.
이러한 충돌은 배열의 길이를 늘리는 등의 방법으로 피하는 것은 비합리적인 방법이다.
충돌의 해결 방법에 따라 테이블의 구조가 달라지는 경우가 있을 정도로
충돌의 해결 방법은 테이블에서 큰 의미를 가진다.
어느 정도 갖춰진 테이블과 해쉬의 구현의 예
앞서 예제를 통해서 테이블과 해수 함수의 구현을 간단히 보였지만,
테이블의 구현사례로는 부족한 감이 있다.
따라서 어느 정도 모습을 갖춰 다시 한번 구현하고자 한다.
#pragma once
#define STR_LEN 50
typedef struct _person
{
int ssn;
char name[STR_LEN];
char addr[STR_LEN];
} Person;
int GetSSN(Person* p);
void ShowPerInfo(Person* p);
Person* MakePersonData(int ssn, char* name, char* addr);#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include "Person.h"
int GetSSN(Person* p)
{
return p->ssn;
}
void ShowPerInfo(Person* p)
{
printf("주민등록번호: %d \n", p->ssn);
printf("이름 : %d \n", p->name);
printf("주소 : %s \n\n", p->addr);
}
Person* MakePersonData(int ssn, char* name, char* addr)
{
Person* newP = (Person*)malloc(sizeof(Person));
newP->ssn = ssn;
strcpy(newP->name, name);
strcpy(newP->addr, addr);
return newP;
}
위는 Person 구조체의 변수(구조체 변수 주소 값) 테이블에 저장될 '값'이다.
그리고 그 중에서 구조체의 멤버 ssn, 즉 주민등록번호를 '키'로 결정하였다.
따라서 키를 별도로 추출하는데 사용하기 위해서 GetSSN 함수를 정의하였다.
그리고 Person 구조체 변수의 생성 및 초기화의 편의를 위해서
MakePersonData 함수도 정의하였다.
#include<stdio.h>
#include <stdlib.h>
#include "Table.h"
void TBLInit(Table* pt, HashFunc* f)
{
int i;
// 모든 슬롯 초기화
for (i = 0; i < MAX_TBL; i++) {
(pt->tbl[i]).status = EMPTY;
}
pt->hf = f; // 해쉬 함수 등록
}
void TBLInsert(Table* pt, Key k, Value v)
{
int hv = pt->hf(k);
pt->tbl[hv].val = v;
pt->tbl[hv].key = k;
pt->tbl[hv].status = INUSE;
}
Value TBLDelete(Table* pt, Key k)
{
int hv = pt->hf(k);
if ((pt->tbl[hv]).status != INUSE) return NULL;
else {
(pt->tbl[hv]).status = DELETED;
return (pt->tbl[hv].val);
}
}
Value TBLSearch(Table* pt, Key k)
{
int hv = pt->hf(k);
if ((pt->tbl[hv]).status != INUSE) return NULL;
else return (pt->tbl[hv]).val;
}
직접 정의한 해쉬 함수를 등록하도록 디자인되었다는 사실과
Slot의 배열로 테이블을 구성하였다는 사실에만 주목하면 나머지는 쉽게 이해할 수 있다.

이로써 우리가 모델로 삼을 수 있는 테이블 구현이 완료되었으며,
하지만 테이블 구현만 완료되었지 '충돌'에 대한 해결책은 담고 있지 않다.
좋은 해쉬 함수의 조건
좋은 해쉬 함수를 사용하면 데이터 테이블의 전체 영역에 슬롯이 고르게 분포된다.
슬롯이 고르게 분포된다는 것은 충돌이 발생할 확률이 낮다는 것을 의미한다.
충돌의 해결책이 마련되어 있더라도, 충돌이 덜 발생해야
데이터의 저장, 삭제 및 탐색의 효율을 높일 수 있다.
때문에 좋은 해쉬 함수는 '충돌을 덜 일으키는 해쉬 함수'라고도 말할 수 있다.
즉 좋은 해쉬 함수는 키의 일부분을 참조하여 해쉬 값을 만들지 않고,
키 전체를 참조하여 해쉬 값을 만들어 낸다.
이는 자릿수 선택(Digit Selection) 방법과 자릿수 폴딩(Digit Folding) 방법에 근거하였다.
키의 특정 위치에서 중복의 비율이 높거나,
아예 공통으로 들어가는 값이 있다면, 이를 제외한 나머지를 가지고
해쉬 값을 생성하는 지극히 상식적인 방법이다.
이와 유사한 방법으리 비트 추출 방법이라는 것이 있다.
이는 탐색 키의 비트 열에서 일부를 추출 및 조합하는 방법이다.
또한 좋은 해쉬 함수를 만들기 위해서 자릿수 폴딩이라는 방법도 있다.
폴딩은 접는다는 뜻으로
2 7 | 3 4 | 1 9 이런식으로 구간을 나누어 겹친 두 자릿수 숫자를 모두 더하면
그 결과는 80이 되는데,
이를 해쉬 값이라 하면 이는 여섯 자리의 숫자를 모두 반영하여 얻은 결과라 할 수 있다.
이렇듯 폴딩 이외에도 키를 제곱하여 그 중 일부를 추출하는 방법,
폴딩의 과정에서 덧셈 대신 XOR 연산을 하는 방법, 등이 있다.
통계적으로 넓은 분포를 보이는 다양한 방법들이 있는데
해쉬 함수를 디자인할 때에는
이러한 방법들보다 키의 특성과 저장공간의 크기를 고려하는 것이 우선이다.
'컴퓨터 프로그래밍 공부 > 자료구조와 알고리즘' 카테고리의 다른 글
| 트리를 이용한 파일 시스템 자료 구조 만들기 (1) | 2024.10.29 |
|---|---|
| 해쉬 테이블 - Collison 문제 해결책 (1) | 2024.10.15 |
| AVL (0) | 2024.09.21 |
| 버블소트 구현 (0) | 2024.08.15 |
| Stack 구현하기 (0) | 2024.08.02 |