가상 메모리를 통해 작은 물리 메모리보다 큰 프로세스도 실행할 수 있다고는 하지만,
그럼에도 불구하고 여전히 물리 메모리의 크기는 한정되어 있다.
운영체제는 프로세스들이
한정된 메모리를 효율적으로 이용할 수 있도록 기존 메모리에 적재된 불필요한 페이지를 선별하여
보조기억장치로 내보낼 수 있어야 하고,
프로세스들에 적절한 수의 프레임을 할당하여 페이지를 할당할 수 있게 해야한다.
이번 게시글에서는 요구 페이징의 개념과 페이지 교체 알고리즘,
그리고 프레임 할당에 대해 학습하며 운영체제가 이러한 기능을 어떻게 수행하는 알아보자.
요구 페이징
프로세스를 메모리에 적재할 때 처음부터 모든 페이지를 적재하지 않고
필요한 페이지만을 메모리에 적재하는 기법을 요구 페이징이라고 한다.
이름 그대로 실행에 요구되는 페이지만 적재 하는 기법이다.
요구 페이지의 기본 양상은 다음과 같다.
1. CPU가 특정 페이지에 접근하는 명령어를 실행한다.
2. 해당 페이지가 현재 메모리에 있을 경우 (유효 비트가 1일 경우)
CPU는 페이지가 적재된 프레임에 접근한다.
3. 해당 페이지가 현재 메모리에 없을 경우 (유효 비트가 0일 경우) 페이지 폴트가 발생한다.
4. 페이지 폴트 처리 루틴은 해당 페이지를 메모리로 적재하고 유효 비트를 1로 설정한다.
5. 다시 1번을 수행한다.
참고로 아무런 페이지도 메모리에 적재하지 않은 채 무작정 실행부터 할 수도 있다.
이 경우 프로세스의 첫 명령어를 실행하는 순간부터 페이지 폴트가 계속 발생하게 되고,
실행에 필요한 페이지가 어느 정도 적재된 이후부터는 페이지 폴트 발생 빈도가 떨어진다.
이를 순수 요구 페이징 기법이라고도 한다.
다시 요구 페이징 이야기로 돌아와서,
위와 같은 요구 페이징 시스템이 안정적으로 작동하려면
필연적으로 다음 두 가지를 해결해야 한다.
하나는 페이지 교체이고, 다른 하나는 프레임 할당이다.
프레임 할당은 조금 뒤에 설명하기로 하고 우선 페이지 교체에 대해 알아보자.
요구 페이징 기법으로 페이지들을 적재하다 보면 언젠가 메모리가 가득 차게 된다.
이때는 당장 실행에 필요한 페이지를 적재하기 위해 메모리에 적재된 페이지를 보조기억장치로 내보내야 한다.
메모리에 적재된 많고 많은 페이지 중 어떤 페이지를 내보내는 것이 최선일까?
이를 결정하는 방법이 페이지 교체 알고리즘이다.
즉 쫓아낼 페이지를 결정하는 방법을 페이지 교체 알고리즘이라고 한다.
페이지 교체 알고리즘
좋은 페이지 교체 알고리즘은 무엇일까?
일반적으로 페이지 폴트를 가장 적게 일으키는 알고리즘을 좋은 알고리즘으로 평가한다.
페이지 폴트가 일어나면 보조기억장치로부터 필요한 페이지를 가져와야 하기 때문에
메모리에 적재된 페이지를 가져오는 것보다 느려지기 때문이다.
가령 한 알고리즘을 통해 고른 페이지를 스왑 아웃시켰을 때
페이지 폴트가 자주 발생하면 이는 좋은 알고리즘이 아니다.
"한 페이지 교체 알고리즘을 선택했더니 페이지 폴트가 자주 발생했다"는 말은
"보조기억장치로 내쫒을 페이지를 잘못 골랐다" 라는 뜻으로,
내보내면 안 되는 페이지를 보조기억장치로 내보냈다는 의미와 같기 때문이다.
이는 당연히 컴퓨터의 성능을 저해하는 나쁜 알고리즘일 것이다.
반면 어떤 알고리즘을 통해 고른 페이지를 스왑 아웃시켜도 페이지 폴트가 자주 발생하지 않는다면
이는 컴퓨터의 성능 저하를 방지하는 좋은 알고리즘으로 평가할 수 있다.
그렇기에 페이지 교체 알고리즘을 제대로 이해하려면 페이지 폴트 횟수를 알 수 있어야 한다.
그리고 페이지 폴트 횟수는 페이지 참조열을 통해 알 수 있다.
페이지 참조열의 개념은 간단하다.
CPU가 참조하는 페이지들 중 연속된 페이지를 생략한 페이지열을 의미한다.
가령 CPU가 아래와 같은 순서로 페이지에 접근했다고 가정해보자.
2 2 2 3 5 5 5 3 3 7
여기서 연속된 페이지를 생략한 페이지열, 다시 말해 아래 숫자열이 페이지 참조 열이다.
2 3 5 3 7
연속된 페이지를 생략하는 이유는 중복된 페이지를 참조하는 행위는 페이지 폴트를 발생시키기 않기 때문이다.
CPU가 특정 페이지에 열 번 연속으로 접근한다고 해서
한 번 접근하는 것보다 페이지 폴트가 많이 발생하지 않는 것 처럼말이다.
페이지 교체 알고리즘을 평가할 때 관심있게 고려할 것은 오직 페이지 폴트의 발생 횟수이기 때문에
어차피 페이지 폴트가 일어나지 않을 연속된 페이지에 대한 참조는 고려하지 않는 것이다.
이제 대표적인 페이지 교체 알고리즘에 대해 하나씩 알아보고 페이지 참조열을 바탕으로
각 알고리즘들의 성능을 평가해 보자.
FIFO 페이지 교체 알고리즘
첫 번째로 소개할 알고리즘은 FIFO 페이지 교체 알고리즘이다.
이는 가장 단순한 방법으로, 이름 그대로 메모리에 가정 먼저 올라온 페이지부터 내쫓는 방식이다.
쉽게 말해 "오래 머물렀다면 나가라"는 알고리즘 이다.
예제를 통해 조금 더 자세히 알아보자.
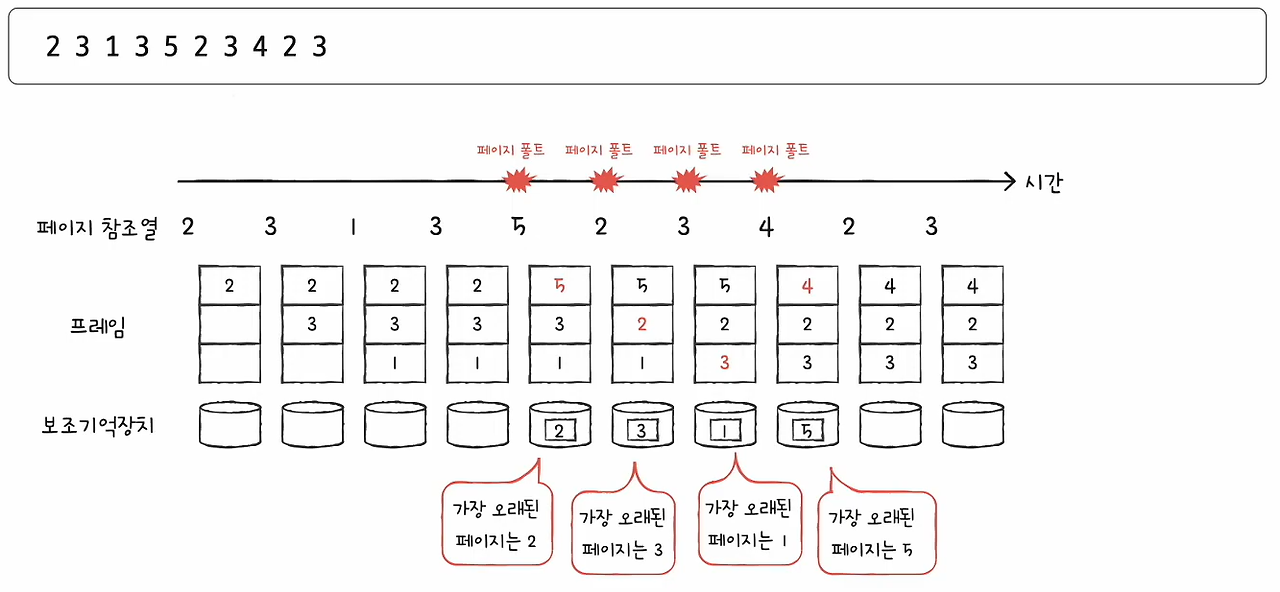
가령 프로세스가 사용할 수 있는 프레임이 세 개 있따고 가정하고
페이지 참조열이 아래와 같다고 해 보자.
2 3 1 3 5 2 3 4 2 3
그렇다면 FIFO 페이지 교체 알고리즘은 아래와 같은 순서대로 진행되어
총 네 번의 페이지 폴트가 발생하게 된다.
페이지가 초기에 적재될 때 발생할 수 있는 페이지 폴트는 고려하지 않고,
적재된 페이지를 교체하기 위해 발생한 페이지 폴트만을 페이지 폴트로 간주했다.
FIFO 페이지 교체 알고리즘은 아이디어와 구현이 간단하지만, 마냥 좋기만 한 것은 아니다.
프로그램 실행 초기에 적재된 페이지 속에는 프로그램 실행 초기에 잠깐 실행되다가
이후에 사용되지 않을 페이지도 있겠지만,
프로그램 실행 내내 사용될 내용을 포함하고 있을 수도 있다.
이런 페이지는 메모리에 먼저 적재되었다고 해서 내쫒아서는 안될테니 말이다.
이러한 단점을 보완하려 나온 것이 2차 기회 페이지 알고리즘이다.
2차 기회 페이지 교체 알고리즘
FIFO 페이지 교체 알고리즘은
자칫 자주 참조되는 페이지가 먼저 적재되었다는 이유만으로 내쫒길 수 있다는 문제가 있었다.
2차 기회 페이지 교체 알고리즘은
이러한 부작용을 어느 정도 개선한 FIFO 페이지 교체 알고리즘의 변형이다.
이름 그대로 한 번 더 기회를 주는 알고리즘이다.
2차 기회 페이지 교체 알고리즘은 FIFO 페이지 교체 알고리즘과 같이 기본적으로
메모리에서 가장 오래 머물렀던 페이지를 대상으로 내보낼 페이지를 선별한다.
차이가 있다면 만일 페이지의 참조 비트가 1일 경우,
당장 내쫒지 않고 참조 비트를 0으로 만든 뒤 현재 시간을 적재 시간으로 설정한다.
메모리에 가장 오래 머물렀다고 할지라도
참조 비트가 1이라는 의미는 CPU가 접근한 적이 있다는 의미이므로
한 번의 기회를 더 주는 셈이다.
메모리에 가장 오래 머무른 페이즈이 참조 비트가 0일 경우 이 페이지는 가장 오래된 페이지이면서
동시에 사용되지 않는 페이지라고 볼 수 있으므로 보조기억 장치로 내보내면 된다.
예를 들어보자.
다섯 개의 프레임을 가진 메모리에 페이지가 3, 1, 5, 2, 4 순으로 적재되었고,
각각의 참조 비트가 아래 그림과 같다고 가정해보자

이런 상황에서 페이지 6이 새롭게 적재되어야 한다고 해 보자.
기존 FIFO 페이지 교체 알고리즘대로였다면 보조기억장치로 내보낼 페이지는 페이지 3이다.
하지만 2차 기회 페이지 교체 알고리즘은 페이지 3의 참조 비트를 보고,
1일 경우 이를 0으로 변경한 뒤 최근에 적재된 페이지로 간주한다.
한번의 기회를 더 주는 것이다.

위 그림에 따르면 다음으로 가장 오랫동안 메모리에 머물렀던 페이지는 페이지 1이다.
참조 비트가 0이니, 즉 페이지 1은 오랫동안 메모리에 머물러 있었으면서
동시에 CPU가 접근하지 않은 페이지인 셈이다.
이 경우 페이지 1을 내보내고 페이지 1이 적재되었던 프레임을 페이지 6을 적재하면 된다.
최적 페이지 교체 알고리즘
최적 페이지 교체 알고리즘은 CPU에 의해 참조되는 횟수를 고려하는 페이지 교체 알고리즘이다.
잘 생각해보면 메모리에 오랫동안 남아야 할 페이지는 자주 사용될 페이지이고,
반대로 메모리에 없어도 될 페이지는 오랫동안 사용되지 않을 페이지인데,
오랜 기간 메모리에 있었던 페이지라고 해서 보조 기억장치로 내쫓는 건 비합리적이라고 볼 수 있다.
따라서 보조기억장치로 내보내야 할 페이지는 앞으로 사용 빈도가 가장 낮은 페이지이므로,
앞으로의 사용의 빈도가 가장 낮은 페이지를 교체하는 알고리즘을
페이지 교체 알고리즘으로 삼는 것이 가장 합리적이다.
이 알고리즘이 최적 페이지 교체 알고리즘이다.
위 예시의 상황에서 프로세스가 사용할 수 있는 프레임이 세 개 있고,
페이지 참조열이 아래와 같다고 해 보자.
2 3 2 1 5 2 3 5
최적 페이지 교체 알고리즘은 아래 그림과 같이
총 두 번의 페이지 폴트가 발생하게 된다.
FIFO 알고리즘에 비하면 페이지 폴트가 훨씬 낮아진 것을 확인할 수 있다.

최적 페이지 교체 알고리즘은 이름 그대로 가낭 낮은 페이지 폴트율을 보장하는 알고리즘이다.
그렇기 때문에 최적 페이지 교체 알고리즘은 위 예시뿐 아니라
최적 교체 알고리즘의 특징으로는
가장 오랫동안 사용되지 않을 페이지를 알고 교체하기 때문에
모든 페이지 교체 알고리즘을 통틀어 가장 페이지 교체 수가 적다. ( = 페이지 폴트 발생 빈도가 가장 낮다)
앞에 있는 페이지를 미리 알아야 하기 때문에 구현이 어렵다는 단점이 있으며,
최적 페이지 교체 알고리즘은 앞으로 오랫동안 사용되지 않을 페이지를 내보내는 알고리즘이다.
LRU 페이지 교체 알고리즘
최적 페이지 알고리즘은 실제 구현이 어려우므로,
최적 알고리즘의 방식과 비슷한 효과를 낼 수 있는 방법을 사용한 것이 LRU 알고리즘이다.
즉
가장 오래동안 사용되지 "않을" 페이지를 교체하는 알고리즘을 구현하기 어렵다면,
이를 조금 변형한
가장 오랫동안 사용되지 "않은" 페이지를 교체하는 알고리즘을 구하는 것이 가능하다.
(least recently used)

스레싱과 프레임 할당
페이지 폴트가 자주 발생하는 이유에 나쁜 페이지 교체 알고리즘만 있는 건 아니다.
프로세스가 사용할 수 있는 프레임 수가 적어도 페이지 폴트는 자주 발생한다.
(사실 이게 더 근본적인 이유이다.)
반대로 프로세스가 사용할 수 있는 프레임 수가 많으면 일반적으로 페이지 폴트 빈도는 감소한다.
즉
실행 중인 프로세스에 프레임을 얼마나 나누어즈냐에 따라 시스템 성능이 달라지며,
너무 적은 프레임을 할당하면 페이지 부재가 빈번히 일어나게되어
너무 많은 프레임을 할당하면 페이지 부재는 줄지만 메모리 낭비를 하여 시스템 성능이 낮아진다.
프로세스에 프레임을 할당하는 방식은 정적 할당과 동적 할당으로 나뉜다.
정적 할당 :
정적 할당 방식은 프로세스 실행 초기에 프레임을 나누어준 후 그 크기를 고정하는 것으로,
'균등 할당 방식'과 '비례 할당 방식'이 있다.
균등 할당 :
균등 할당 방식은 프로세스의 크기와 상관없이 사용 가능한 프레임을 모든 프로세스에 동일하게 할당된다.

균등 할당 방식에서는 크기가 큰 프로세스의 경우
필요한 만큼 할당받지 못해 부재가 빈번히 일어나게되고,
크기가 작은 프로세스의 경우 메모리가 낭비된다.
비례 할당 :
비례 할당 방식은 프로세스의 크기에 비례하여 프레임을 할당하는 방식이다.

비례 할당 방식은 프로세스가 실행 중에 필요로 하는 프레임을 유동적으로 반영하지 못한다.
아무리 작은 프로세스라도 실행 중에 많은 메모리 (프레임)을 필요로 하는 경우가 있다.
또한 사용하지 않을 메모리를 처음부터 미리 확보하여 공간을 낭비한다.
동적 할당 :
정적 할당 방식은 프로세스를 실행하는 초기에 프레임을 할당하기 때문에
프로세스를 실행하는 동안 메모리 요구를 반영하지 못하는 단점이 있다.
동적 할당은 변하는 요청을 수용하는 방식으로
'작업집합 모델'과 '페이지 부재 빈도'를 사용하는 방식이 있다.
작업집합 모델 :
작업집합 모델은 지역성 이론을 바탕으로 하며,
가장 최근에 접근한 프레임이 이후이에도 참조될 가능성이 높다는 가정이다.
최근 일정 시간 동안 참조된 페이지들을 집합으로 만들고, 이 집합을 물리 메모리에 유지한다.

'작업집합 크기'는 물리 메모리에 유지할 페이지의 크기이며, 작업집합에 들어갈 최대 페이지 수를 의미한다.
작업집합에 포함되는 페이지의 범위를 '작업집합 윈도우' 라고 한다.
위 그림은 작업집합 크기를 5로 설정하고, 작업집합 윈도우를 10으로 잡았다.
이때 작업집합 윈도우에는 현재 시점(t1)부터 시간적으로 가까운 페이지부터 삽입된다.
또한 작업집합 크기가 6라는 것은 페이지에 다섯 번 접근할 때마다 작업집합을 갱신한다는 의미이다.
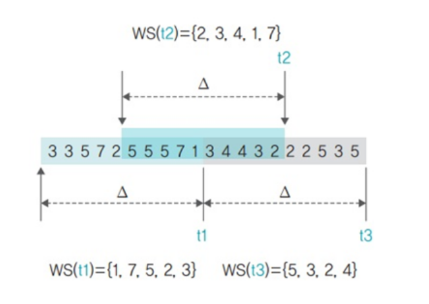
작업집합 크기를 5로 설정했기 때문에 t1 시점 이후에 5개 페이지에 접근하면 t2 시점에 작업집합이 갱신된다.
그러나 t2 시점에 가까운 순서대로 삽입되고, 가장 멀리있는 5번 페이지는 작업 집합에 속하지 못하게 된다.
작업집합 윈도우를 너무 크게 잡으면 필요 없는 페이지가 메모리에 남아 다른 프로세스에 영향을 미친다.
반대로 너무 작게 잡으면 필요한 페이지가 스왑 영역으로 옮겨져 성능이 떨어진다.
페이지 부재 빈도 :
작업집합 모델의 경우 충분한 페이지를 할당하지 않으면
작업집합에 있는 페이지를 물리 메모리에 유지하기 힘들다.
즉 프로세스의 성능을 높이는 방법이지만 스레싱 문제를 해결하지 못한다.
페이지 부재 빈도를 이용하는 것은 프로세스가 필요로 하는 페이지의 양을 동적으로 결정하는 방법이다.
페이지 부재 비율이 상한선으로 초과하면 할당한 프레임이 적다는 것으로 늘리고,
하한선 밑으로 내려가면 메모리가 낭비된다는 의미로 프레임을 회수한다.

'컴퓨터 구조 + 운영체제' 카테고리의 다른 글
| 파일 시스템 (0) | 2024.04.21 |
|---|---|
| 파일과 디렉터리 (1) | 2024.04.21 |
| 가상 메모리 - 연속 메모리 할당 (1) | 2024.04.18 |
| 주소 바인딩 (0) | 2024.04.16 |
| 코어와 멀티코어, 스레드와 멀티스레드 (0) | 2024.04.09 |